Exploring the Differential Transformer: A Step Forward in Language Modeling

Introduction
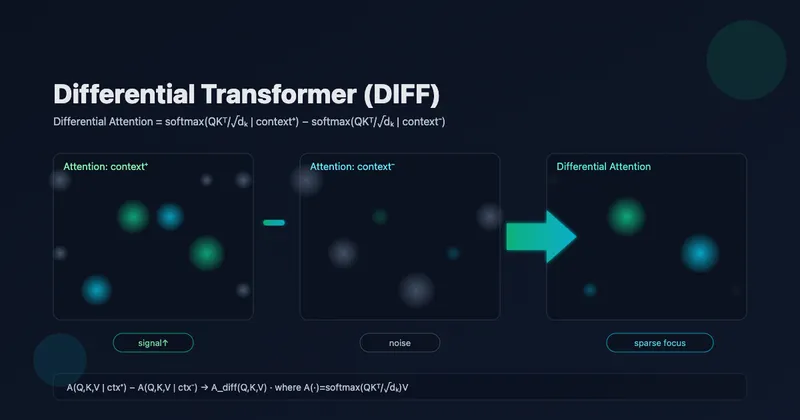
The DIFF Transformer is a new variant of the standard Transformer that enhances the model’s ability to focus on relevant context while canceling out irrelevant noise. It introduces a differential attention mechanism, which calculates attention scores by subtracting one attention map from another. This approach is similar to how noise-canceling headphones work, effectively amplifying the important signals and reducing distractions from irrelevant information.
Diff Transformer
Multi-Head Differential Attention
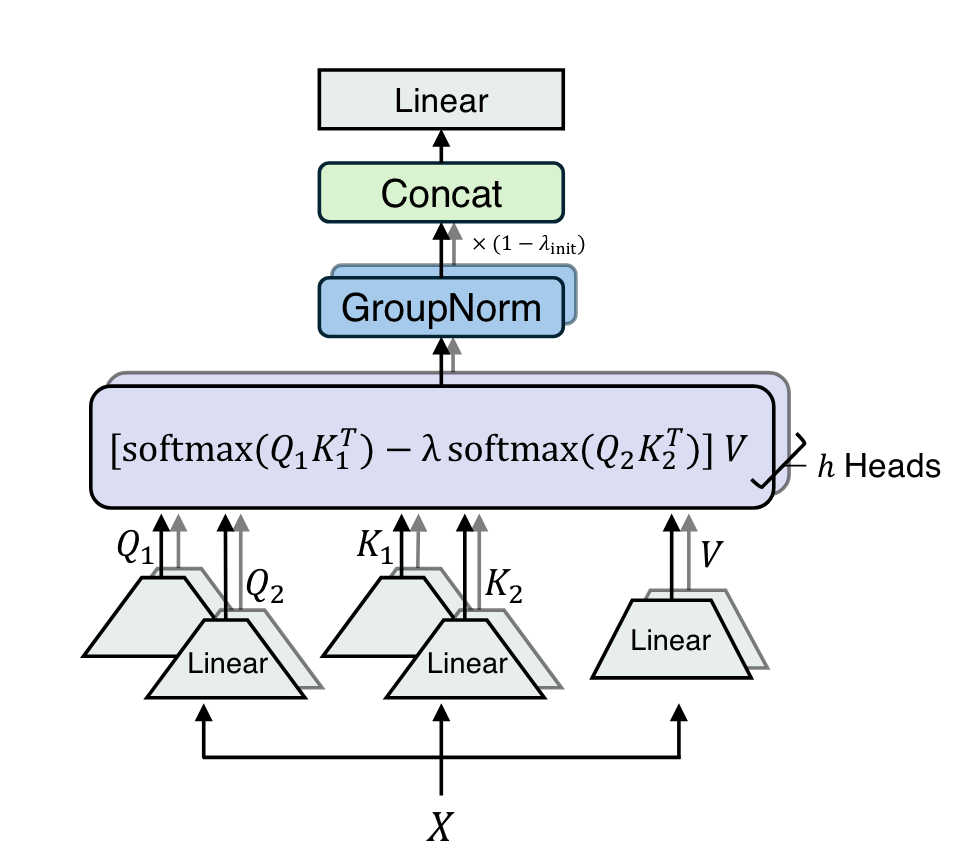 The DIFF Transformer extends this concept to multi-head attention, where each head computes attention scores independently. The model then combines these scores and applies a final linear transformation to produce the output. This multi-head differential attention mechanism allows the model to capture different aspects of the input and focus on specific parts of the context, enhancing its ability to learn complex patterns and relationships.
The DIFF Transformer extends this concept to multi-head attention, where each head computes attention scores independently. The model then combines these scores and applies a final linear transformation to produce the output. This multi-head differential attention mechanism allows the model to capture different aspects of the input and focus on specific parts of the context, enhancing its ability to learn complex patterns and relationships.
Headwise Normalization
Overall Architecture
Key Contributions
Noise-Canceling Attention Mechanism
The DIFF Transformer introduces a unique method of computing attention scores by dividing query and key vectors into two groups. It calculates attention maps for each group, then subtracts one from the other. This subtraction helps to eliminate what the authors call “attention noise,” allowing the model to better focus on important context. As a result, the model achieves a higher signal-to-noise ratio, which is crucial for tasks requiring precision, such as key information retrieval in long contexts.
Scaling Efficiency
One of the standout advantages of DIFF Transformer is its efficiency in scaling. The authors demonstrate that their model can achieve performance comparable to standard Transformers with approximately 65% fewer parameters or tokens. This scaling benefit positions DIFF Transformer as a more resource-efficient alternative, especially for tasks that require large-scale language models.
Long-Context Handling
The paper highlights DIFF Transformer’s superior performance in long-context tasks, where the model must handle extended sequences of information. In evaluations of up to 64K tokens, the DIFF Transformer consistently outperforms traditional models, effectively maintaining high accuracy even as the context length increases. This makes the architecture particularly valuable for applications like document retrieval, summarization, and long-form question answering.
Mitigating Hallucinations
LLMs are notorious for generating incorrect or “hallucinated” information, especially in tasks where the context is vast or ambiguous. DIFF Transformer reduces hallucinations by concentrating attention on the relevant parts of the input. In tests on summarization and question-answering tasks, DIFF Transformer exhibited a noticeable reduction in hallucinations compared to standard models.
Robust In-Context Learning
Another area where DIFF Transformer shines is in in-context learning, where a model learns from examples provided in its input. The paper shows that DIFF Transformer not only improves accuracy in in-context learning tasks but also exhibits greater robustness to variations in the order of input examples, an issue that has traditionally plagued LLMs.
Evaluation
Conclusion
The Differential Transformer represents a significant leap forward in the design of attention mechanisms for LLMs. By addressing the persistent issue of attention noise, this architecture improves the performance of language models across several key tasks, particularly those involving long-context understanding and in-context learning. As LLMs continue to scale, the efficiency and robustness of architectures like DIFF Transformer will play an increasingly important role in shaping the future of NLP.
I’ve some curiosity to see how
Explore More
For those interested in diving deeper into Differential Transformer, check out the resources provided by the researchers