PPO for Language Models: The RLHF Workhorse
Part 2 of 4: The Industry Standard
TL;DR: PPO (Proximal Policy Optimization) is the backbone of RLHF, powering ChatGPT, Claude, and most aligned LLMs. It provides stable training through clipped objectives and flexible advantage estimation via GAE. But this comes at a cost: four models (policy, reference, value, reward) straining GPU memory. Understanding PPO deeply reveals why simpler alternatives like GRPO emerged.
Reading time: ~28 minutes
Prerequisites: Part 1: RL Foundations covers policy gradients, value functions, and advantage estimation.
From REINFORCE to PPO
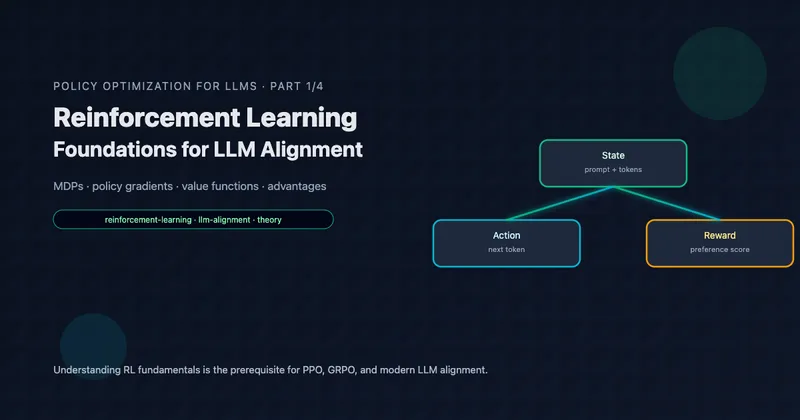
In Part 1, we saw that policy gradients are powerful but suffer from high variance. Actor-critic methods add a value function to reduce variance, but introduce their own challenges: training two networks that must improve together without destabilizing each other.
PPO (Proximal Policy Optimization) addresses stability through a deceptively simple idea: limit how much the policy can change in a single update. If updates are small enough, the value function doesn’t become stale, and training remains stable.
But “small updates” is vague. How do we formalize it? And how do we enforce it efficiently?
The Trust Region Idea
The Problem with Large Updates
Consider what happens when we take a policy gradient step:
- Collect trajectories using current policy
- Compute advantages using value function
- Update:
The problem: our advantages were computed for , but we’re evaluating actions under . If changes too much, the advantages become stale—they no longer reflect the true quality of actions under the new policy.
This can cause:
- Overshooting: A good action gets reinforced too strongly
- Policy collapse: All probability mass shifts to one action
- Training instability: Performance oscillates wildly
Trust Regions: The Concept
A trust region is a constraint on how much the policy can change:
where is some distance measure between policies, and is a small threshold.
Within the trust region, our local approximation (using old advantages) is valid. Outside it, we can’t trust our gradient estimates.
TRPO: The Principled Approach
Trust Region Policy Optimization (TRPO) uses KL divergence as the distance:
TRPO solves this constrained optimization using second-order methods (conjugate gradient + line search). It’s theoretically elegant but:
- Computationally expensive
- Complex to implement
- Hard to parallelize
This motivated PPO: can we get trust region benefits with first-order methods?
From TRPO to PPO: The Clipped Objective
PPO’s insight: instead of enforcing a hard constraint, clip the objective so that updates beyond the trust region give no additional benefit.
The Importance Sampling Ratio
First, we rewrite the policy gradient using importance sampling:
Define the importance ratio:
When , we have . As diverges from , moves away from 1.
The Clipped Surrogate Objective
PPO’s objective clips the ratio to prevent large updates:
Let’s unpack this carefully.
How Clipping Works
Case 1: Positive advantage () — the action was good
We want to increase , which increases .
- If : The objective is , so gradients push higher
- If : The clipped term becomes , which is constant. No gradient — we’ve increased the action probability enough
Case 2: Negative advantage () — the action was bad
We want to decrease , which decreases .
- If : The objective is , so gradients push lower
- If : The clipped term becomes , which is constant. No gradient — we’ve decreased the action probability enough
The “Pessimistic” Bound
The in the objective creates a pessimistic bound: we take the worse of (unclipped, clipped) for each term.
- For good actions: Can’t get more than benefit
- For bad actions: Can’t get less than penalty
This is conservative by design—it prevents the optimizer from exploiting stale advantages.
Why ?
The canonical choice is , allowing to range from 0.8 to 1.2. This means:
- Action probabilities can at most increase by 20% (relative)
- Action probabilities can at most decrease by 20% (relative)
per update step. Empirically, this balances stability and learning speed. Some implementations use 0.1 for more conservative updates.
Key Insight: PPO’s clipping creates a “soft trust region” using only first-order optimization. The policy can change, but changes beyond provide no additional gradient signal. It’s not a hard constraint, but it works remarkably well in practice.
Generalized Advantage Estimation (GAE)
PPO pairs the clipped objective with Generalized Advantage Estimation (GAE), a flexible way to estimate advantages.
The Bias-Variance Tradeoff
Recall from Part 1 that we can estimate advantages in different ways:
Monte Carlo (MC):
- Unbiased: Uses actual returns
- High variance: Includes all future randomness
Temporal Difference (TD):
- Biased: Uses estimated instead of true expected return
- Low variance: Only one step of randomness
GAE: Interpolating Between MC and TD
GAE introduces parameter to interpolate:
where is the TD error.
Special cases:
- : (TD, low variance, high bias)
- : (MC, high variance, low bias)
Practical Computation
GAE can be computed efficiently backwards through the trajectory:
Starting from the end of the episode ( or ), we recurse backwards.
def compute_gae(rewards, values, gamma=0.99, lam=0.95):
"""
Compute GAE advantages.
Args:
rewards: [T] rewards at each timestep
values: [T+1] value estimates (includes bootstrap V(s_T+1))
gamma: Discount factor
lam: GAE lambda parameter
Returns:
advantages: [T] GAE advantage estimates
"""
T = len(rewards)
advantages = torch.zeros(T)
last_adv = 0
for t in reversed(range(T)):
# TD error: δ_t = r_t + γV(s_{t+1}) - V(s_t)
delta = rewards[t] + gamma * values[t + 1] - values[t]
# GAE recursion: A_t = δ_t + γλ A_{t+1}
advantages[t] = delta + gamma * lam * last_adv
last_adv = advantages[t]
return advantages
Choosing
| Value | Bias | Variance | Best For |
|---|---|---|---|
| 0.0 | High | Low | When value function is very accurate |
| 0.9 | Medium | Medium | Typical choice |
| 0.95 | Low-Medium | Medium-High | Default in most PPO implementations |
| 1.0 | None | High | When value function is poor |
The default works well across many domains, including LLM fine-tuning.
Key Insight: GAE lets us tune the bias-variance tradeoff. High trusts actual returns more; low trusts the value function more. For LLMs with sparse rewards, higher is often better since the value function may be inaccurate at intermediate states.
The Complete PPO Algorithm
Now let’s put it all together.
PPO-Clip Algorithm
Algorithm: PPO-Clip
Hyperparameters:
ε (clip ratio, typically 0.2)
γ (discount, typically 0.99 or 1.0)
λ (GAE lambda, typically 0.95)
K (epochs per batch, typically 3-10)
M (minibatch size)
Initialize: Policy π_θ, Value function V_ψ
For iteration = 1, 2, ...:
┌─────────────────────────────────────────────────────┐
│ Phase 1: Collect Experience │
│ ─────────────────────────────────────────────────── │
│ Run π_θ for T timesteps, collecting: │
│ {s_t, a_t, r_t, s_{t+1}} for t = 1...T │
│ │
│ Compute value estimates V_ψ(s_t) for all t │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ Phase 2: Compute Advantages │
│ ─────────────────────────────────────────────────── │
│ For t = T-1 down to 0: │
│ δ_t = r_t + γV_ψ(s_{t+1}) - V_ψ(s_t) │
│ Â_t = δ_t + γλ Â_{t+1} (GAE) │
│ │
│ Compute returns: R̂_t = Â_t + V_ψ(s_t) │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ Phase 3: Optimization (K epochs) │
│ ─────────────────────────────────────────────────── │
│ For epoch = 1 to K: │
│ For each minibatch of size M: │
│ │
│ # Policy loss (clipped) │
│ ρ = π_θ(a|s) / π_θ_old(a|s) │
│ L_clip = min(ρÂ, clip(ρ, 1-ε, 1+ε)Â) │
│ L_policy = -mean(L_clip) │
│ │
│ # Value loss │
│ L_value = mean((V_ψ(s) - R̂)²) │
│ │
│ # Entropy bonus (optional) │
│ L_entropy = -mean(H[π_θ(·|s)]) │
│ │
│ # Combined loss │
│ L = L_policy + c_v·L_value + c_e·L_entropy │
│ │
│ Update θ, ψ using gradient of L │
│ │
│ Update π_θ_old ← π_θ │
└─────────────────────────────────────────────────────┘
The Three Loss Components
1. Policy Loss (maximize)
2. Value Loss (minimize)
where is the target return.
3. Entropy Bonus (maximize)
Encourages exploration by preventing premature convergence to deterministic policies.
Why Multiple Epochs?
PPO reuses collected data for epochs (typically 3-10). This improves sample efficiency—we extract more learning from each batch of experience.
The clipping ensures this is safe: even with multiple passes, the policy can’t change too drastically because updates beyond provide no gradient.
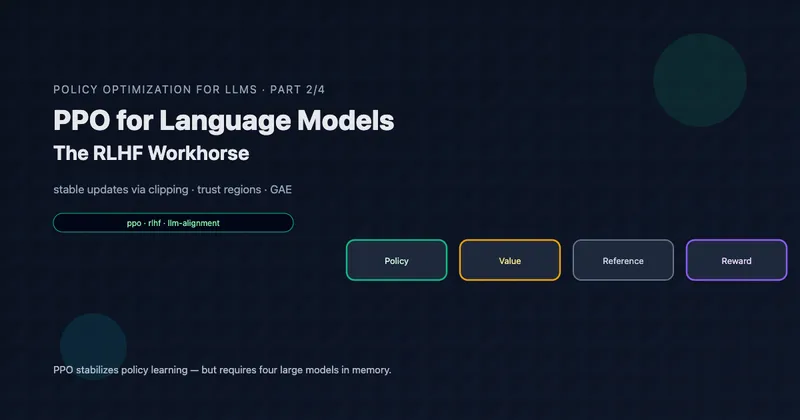
PPO for LLMs: The Four-Model Problem
When applying PPO to LLM alignment, we need four separate models:
Memory Requirements (7B Model Example)
| Model | Training? | Memory |
|---|---|---|
| Policy | ✅ Yes | ~28 GB (weights + gradients + optimizer) |
| Reference | ❌ Frozen | ~14 GB |
| Value | ✅ Yes | ~28 GB |
| Reward | ❌ Frozen | ~14 GB |
| Total | ~84 GB |
This is before accounting for activations, KV cache, and batch processing. For a 7B model, you need multiple A100-80GB GPUs just for the model weights.
Why Each Model is “Necessary”
Policy: Obviously needed—this is what we’re training.
Reference: Needed for KL penalty to prevent reward hacking. Without it, the policy might find exploits in the reward model.
Value: Needed for GAE advantage estimation. This is where PPO’s memory cost comes from.
Reward: Needed to provide training signal. Could potentially be called as an API, but latency becomes an issue.
The Value Network’s Burden
The value network is particularly problematic:
- Same size as policy: For accurate value estimates, the value network should have similar capacity
- Learns a different task: Predicting expected reward vs. generating text
- Sparse reward signal: With rewards only at episode end, value learning is difficult
- Coupled training: Value must improve alongside policy; either failing destabilizes both
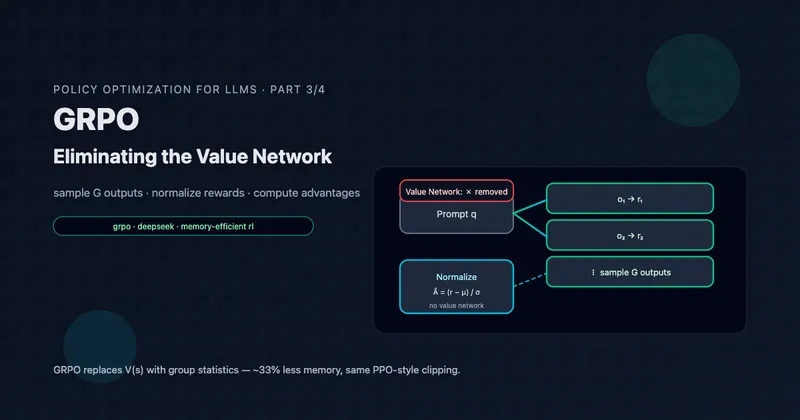
The key question GRPO asks: Do we actually need a learned value network? Can we estimate advantages some other way?
KL Penalties and Reward Shaping
The KL Divergence Constraint
RLHF adds a KL penalty to prevent the policy from diverging too far from the reference:
The coefficient controls the penalty strength:
- High : Policy stays close to reference, may under-optimize reward
- Low : Policy can diverge more, risk of reward hacking
Why KL Penalty Matters
Without KL penalty, several failure modes emerge:
1. Reward Hacking The policy finds patterns that score high on the reward model but don’t represent genuine quality. For example, excessive hedging phrases like “I think” that reward models might prefer.
2. Mode Collapse The policy converges to generating the same high-reward response regardless of prompt, losing diversity.
3. Capability Loss The policy forgets useful behaviors from pretraining that weren’t represented in the reward model.
KL in the Reward vs. KL in the Loss
There are two ways to incorporate KL:
In the reward (standard PPO-RLHF):
This couples KL with the reward, affecting advantage estimation.
In the loss directly (GRPO’s approach):
This decouples KL from advantages, simplifying the optimization.
PyTorch Implementation
Here’s a complete, educational PPO implementation for LLM fine-tuning:
"""
Proximal Policy Optimization (PPO) for LLM Fine-Tuning
======================================================
Educational implementation emphasizing clarity over optimization.
For production, use libraries like TRL or VERL.
"""
import torch
import torch.nn.functional as F
from torch import Tensor
from dataclasses import dataclass
from typing import Tuple, Optional
@dataclass
class PPOConfig:
"""PPO hyperparameters."""
# Core PPO
clip_epsilon: float = 0.2 # ε: clipping parameter
gamma: float = 1.0 # Discount (1.0 for finite episodes)
gae_lambda: float = 0.95 # λ: GAE parameter
# Loss coefficients
vf_coef: float = 0.5 # Value function loss weight
entropy_coef: float = 0.01 # Entropy bonus weight
# Training
ppo_epochs: int = 4 # K: epochs per batch
max_grad_norm: float = 0.5 # Gradient clipping
# KL penalty
kl_coef: float = 0.1 # β: KL penalty coefficient
target_kl: float = 0.01 # Target KL for early stopping
def compute_gae(
rewards: Tensor,
values: Tensor,
dones: Tensor,
gamma: float = 1.0,
lam: float = 0.95,
) -> Tuple[Tensor, Tensor]:
"""
Compute Generalized Advantage Estimation.
Args:
rewards: [batch, seq_len] rewards at each step
values: [batch, seq_len + 1] value estimates
dones: [batch, seq_len] episode termination flags
gamma: Discount factor
lam: GAE lambda
Returns:
advantages: [batch, seq_len] GAE advantages
returns: [batch, seq_len] discounted returns
"""
batch_size, seq_len = rewards.shape
advantages = torch.zeros_like(rewards)
last_adv = torch.zeros(batch_size, device=rewards.device)
# Backward pass through sequence
for t in reversed(range(seq_len)):
# Mask for non-terminal states
non_terminal = 1.0 - dones[:, t]
# TD error: δ_t = r_t + γV(s_{t+1}) - V(s_t)
delta = rewards[:, t] + gamma * values[:, t + 1] * non_terminal - values[:, t]
# GAE: A_t = δ_t + γλ A_{t+1}
advantages[:, t] = delta + gamma * lam * non_terminal * last_adv
last_adv = advantages[:, t]
# Returns = advantages + values
returns = advantages + values[:, :-1]
return advantages, returns
def compute_policy_loss(
log_probs: Tensor,
old_log_probs: Tensor,
advantages: Tensor,
clip_epsilon: float = 0.2,
) -> Tuple[Tensor, Tensor]:
"""
Compute PPO clipped policy loss.
Args:
log_probs: [batch, seq_len] current policy log probs
old_log_probs: [batch, seq_len] old policy log probs
advantages: [batch, seq_len] advantage estimates
clip_epsilon: Clipping parameter ε
Returns:
policy_loss: Scalar loss (to minimize)
clip_fraction: Fraction of samples clipped
"""
# Importance ratio: ρ = π_θ / π_old
ratio = torch.exp(log_probs - old_log_probs)
# Clipped ratio
clipped_ratio = torch.clamp(ratio, 1 - clip_epsilon, 1 + clip_epsilon)
# PPO objective: min(ρA, clip(ρ)A)
policy_loss_1 = ratio * advantages
policy_loss_2 = clipped_ratio * advantages
policy_loss = -torch.min(policy_loss_1, policy_loss_2).mean()
# Metrics
clip_fraction = ((ratio - 1).abs() > clip_epsilon).float().mean()
return policy_loss, clip_fraction
def compute_value_loss(
values: Tensor,
returns: Tensor,
old_values: Optional[Tensor] = None,
clip_epsilon: float = 0.2,
clip_value: bool = True,
) -> Tensor:
"""
Compute value function loss, optionally with clipping.
Args:
values: [batch, seq_len] current value estimates
returns: [batch, seq_len] target returns
old_values: [batch, seq_len] old value estimates (for clipping)
clip_epsilon: Clipping parameter
clip_value: Whether to clip value updates
Returns:
value_loss: Scalar loss
"""
if clip_value and old_values is not None:
# Clipped value loss (prevents large value updates)
values_clipped = old_values + torch.clamp(
values - old_values, -clip_epsilon, clip_epsilon
)
value_loss_1 = F.mse_loss(values, returns, reduction='none')
value_loss_2 = F.mse_loss(values_clipped, returns, reduction='none')
value_loss = torch.max(value_loss_1, value_loss_2).mean()
else:
value_loss = F.mse_loss(values, returns)
return value_loss
def compute_entropy_bonus(log_probs: Tensor, probs: Tensor) -> Tensor:
"""
Compute entropy bonus for exploration.
H[π] = -Σ π(a) log π(a)
Args:
log_probs: Log probabilities
probs: Probabilities
Returns:
entropy: Scalar entropy (to maximize)
"""
entropy = -(probs * log_probs).sum(dim=-1).mean()
return entropy
def compute_kl_penalty(
log_probs: Tensor,
ref_log_probs: Tensor,
) -> Tensor:
"""
Compute KL divergence from reference policy.
Uses the approximation: KL ≈ (log π_θ - log π_ref)
Args:
log_probs: [batch, seq_len] current policy
ref_log_probs: [batch, seq_len] reference policy
Returns:
kl: Scalar KL divergence estimate
"""
kl = (log_probs - ref_log_probs).mean()
return kl
class PPOTrainer:
"""
PPO trainer for LLM fine-tuning.
Requires four models:
- policy_model: The LLM being trained
- value_model: Estimates V(s) for advantage computation
- reference_model: Frozen copy for KL penalty
- reward_model: Scores complete responses
"""
def __init__(
self,
policy_model: torch.nn.Module,
value_model: torch.nn.Module,
reference_model: torch.nn.Module,
reward_model: torch.nn.Module,
tokenizer,
config: PPOConfig,
):
self.policy = policy_model
self.value = value_model
self.reference = reference_model
self.reward_fn = reward_model
self.tokenizer = tokenizer
self.config = config
# Freeze reference
for param in self.reference.parameters():
param.requires_grad = False
# Optimizers (separate for policy and value)
self.policy_optimizer = torch.optim.AdamW(
self.policy.parameters(), lr=1e-6
)
self.value_optimizer = torch.optim.AdamW(
self.value.parameters(), lr=1e-5
)
@torch.no_grad()
def generate_experience(
self,
prompts: list[str],
max_length: int = 512,
) -> dict:
"""
Generate responses and compute rewards.
Returns dict with all data needed for PPO update.
"""
# Tokenize prompts
prompt_encodings = self.tokenizer(
prompts, return_tensors="pt", padding=True
)
prompt_ids = prompt_encodings["input_ids"]
prompt_mask = prompt_encodings["attention_mask"]
prompt_len = prompt_ids.shape[1]
# Generate responses
self.policy.eval()
outputs = self.policy.generate(
input_ids=prompt_ids,
attention_mask=prompt_mask,
max_new_tokens=max_length,
do_sample=True,
temperature=1.0,
return_dict_in_generate=True,
output_scores=True,
)
sequences = outputs.sequences
response_ids = sequences[:, prompt_len:]
batch_size, response_len = response_ids.shape
# Get log probs from policy
policy_outputs = self.policy(sequences, return_dict=True)
policy_logits = policy_outputs.logits[:, prompt_len-1:-1, :]
policy_log_probs = F.log_softmax(policy_logits, dim=-1)
policy_log_probs = policy_log_probs.gather(
dim=-1, index=response_ids.unsqueeze(-1)
).squeeze(-1)
# Get log probs from reference
ref_outputs = self.reference(sequences, return_dict=True)
ref_logits = ref_outputs.logits[:, prompt_len-1:-1, :]
ref_log_probs = F.log_softmax(ref_logits, dim=-1)
ref_log_probs = ref_log_probs.gather(
dim=-1, index=response_ids.unsqueeze(-1)
).squeeze(-1)
# Get value estimates
value_outputs = self.value(sequences, return_dict=True)
# Assuming value head outputs scalar per position
values = value_outputs.logits[:, prompt_len-1:, 0] # [batch, response_len + 1]
# Compute rewards (sparse: only at end)
rewards = torch.zeros(batch_size, response_len)
for i in range(batch_size):
response_text = self.tokenizer.decode(response_ids[i])
prompt_text = prompts[i]
rewards[i, -1] = self.reward_fn(prompt_text, response_text)
# Add KL penalty to rewards
kl_penalty = self.config.kl_coef * (policy_log_probs - ref_log_probs)
rewards = rewards - kl_penalty
# Create done mask (only last token is "done")
dones = torch.zeros(batch_size, response_len)
dones[:, -1] = 1.0
# Compute GAE
advantages, returns = compute_gae(
rewards, values,
dones,
gamma=self.config.gamma,
lam=self.config.gae_lambda,
)
# Normalize advantages
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
return {
"sequences": sequences,
"response_ids": response_ids,
"old_log_probs": policy_log_probs.detach(),
"old_values": values[:, :-1].detach(),
"advantages": advantages,
"returns": returns,
"ref_log_probs": ref_log_probs,
}
def train_step(self, experience: dict) -> dict:
"""
Perform PPO update on collected experience.
Args:
experience: Dict from generate_experience()
Returns:
metrics: Training metrics
"""
sequences = experience["sequences"]
response_ids = experience["response_ids"]
old_log_probs = experience["old_log_probs"]
old_values = experience["old_values"]
advantages = experience["advantages"]
returns = experience["returns"]
prompt_len = sequences.shape[1] - response_ids.shape[1]
metrics = {
"policy_loss": 0,
"value_loss": 0,
"entropy": 0,
"kl": 0,
"clip_fraction": 0,
}
# Multiple epochs over the same data
for epoch in range(self.config.ppo_epochs):
self.policy.train()
self.value.train()
# Forward pass - policy
policy_outputs = self.policy(sequences, return_dict=True)
policy_logits = policy_outputs.logits[:, prompt_len-1:-1, :]
policy_log_probs = F.log_softmax(policy_logits, dim=-1)
policy_log_probs = policy_log_probs.gather(
dim=-1, index=response_ids.unsqueeze(-1)
).squeeze(-1)
# Forward pass - value
value_outputs = self.value(sequences, return_dict=True)
values = value_outputs.logits[:, prompt_len-1:-1, 0]
# Compute losses
policy_loss, clip_frac = compute_policy_loss(
policy_log_probs, old_log_probs, advantages,
self.config.clip_epsilon
)
value_loss = compute_value_loss(
values, returns, old_values,
self.config.clip_epsilon
)
# KL for early stopping
kl = compute_kl_penalty(policy_log_probs, old_log_probs)
# Combined loss
loss = (
policy_loss
+ self.config.vf_coef * value_loss
)
# Backward and update
self.policy_optimizer.zero_grad()
self.value_optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(
self.policy.parameters(), self.config.max_grad_norm
)
torch.nn.utils.clip_grad_norm_(
self.value.parameters(), self.config.max_grad_norm
)
self.policy_optimizer.step()
self.value_optimizer.step()
# Track metrics
metrics["policy_loss"] += policy_loss.item()
metrics["value_loss"] += value_loss.item()
metrics["kl"] += kl.item()
metrics["clip_fraction"] += clip_frac.item()
# Early stopping on KL
if kl.item() > self.config.target_kl * 1.5:
break
# Average metrics
for k in metrics:
metrics[k] /= (epoch + 1)
return metrics
PPO’s Limitations for LLMs
Despite its success, PPO has significant drawbacks for LLM alignment:
1. Memory Overhead
The four-model architecture is expensive:
- For 7B models: ~84 GB just for weights
- Doesn’t include activations, optimizer states, or gradients
- Often requires model parallelism even on high-end GPUs
2. Value Function Challenges
The value network faces unique difficulties in LLM settings:
Sparse rewards: With rewards only at episode end, the value function must predict final reward from intermediate states. Early in generation, this prediction is extremely noisy.
State space complexity: The “state” is all possible text prefixes—an enormous, structured space. Learning accurate values across this space is hard.
Representation mismatch: The value network uses the same architecture as a language model, but predicts scalars instead of generating text. This may not be optimal.
3. Implementation Complexity
PPO has many moving parts:
- GAE computation with proper masking
- Clipping with correct sign handling
- Value function clipping (optional but common)
- Entropy bonus tuning
- KL penalty in rewards
- Multiple epochs with early stopping
Each component requires careful implementation and debugging.
4. Hyperparameter Sensitivity
PPO performance depends on many hyperparameters:
- Clip epsilon (ε)
- GAE lambda (λ)
- Value function coefficient
- Entropy coefficient
- KL penalty coefficient
- Learning rates for policy and value
- Number of PPO epochs
Tuning these for each new task and model size is time-consuming.
5. Sample Efficiency
PPO is on-policy: data from old policies can’t be reused directly. Each batch of experience trains for K epochs, then is discarded. For expensive LLM generation, this can be wasteful.
These limitations motivate GRPO: What if we could eliminate the value network entirely? What if advantages could be computed without learning V(s)? Part 3 explores this elegant alternative.
Key Takeaways
Trust Regions
- Large policy updates destabilize training
- TRPO uses hard KL constraints (expensive)
- PPO uses clipping (simple, effective)
The Clipped Objective
- Limits how much action probabilities can change
- Provides “soft” trust region with first-order optimization
- Default
Generalized Advantage Estimation
- Interpolates between TD (low variance) and MC (low bias)
- Default
- Computed efficiently with backward recursion
The Four-Model Problem
- Policy, Reference, Value, Reward
- ~84 GB for 7B model (weights only)
- Value network is the memory bottleneck
PPO’s Challenges for LLMs
- Memory overhead from value network
- Sparse rewards make value learning hard
- Implementation complexity
- Hyperparameter sensitivity
What’s Next
In Part 3: GRPO, we’ll see how DeepSeek eliminates the value network entirely:
- Group-relative advantages from sampled outputs
- 33% memory reduction
- Simpler implementation
- Equal or better performance
The insight is elegant: instead of learning to predict expected reward, just sample multiple outputs and compare them directly.
Further Reading
Original Papers:
- Proximal Policy Optimization Algorithms (Schulman et al., 2017)
- Trust Region Policy Optimization (Schulman et al., 2015)
- High-Dimensional Continuous Control Using Generalized Advantage Estimation (Schulman et al., 2015 — GAE)
LLM Applications:
- Training language models to follow instructions with human feedback (InstructGPT)
- Constitutional AI: Harmlessness from AI Feedback (Anthropic)
Implementations:
Article series
Policy Optimization for LLMs: From Fundamentals to Production
- Part 1 Reinforcement Learning Foundations for LLM Alignment
- Part 2 PPO for Language Models: The RLHF Workhorse
- Part 3 GRPO: Eliminating the Value Network
- Part 4 GDPO: Multi-Reward RL Done Right